Hello, obdobně jako u internetových prohlížečů přemýšlím nad bezpečností dat v use casech, kdy nechci jejich provozovateli předávat citlivé informace – nemluvím o konkrétních údajích jako datum narození, jako spíše obecně o mém stylu uvažování atd.
Máte tipy ať už na konkrétní, „bezpečnější” GPTs, nebo kombinaci kroků (nelogovat se, zakázat učení na mých promptech, psát prompty specifickým způsobem, …)? Díky!
Hodně záleží na tom, o jaká data se jedná (tzn. jaká je jejich klasifikace, jak citlivá jsou, kdo je klientem atd.), ale obecně jsem u klientů řešil následující:
1. Minimalizace dat → odebrání dat, co nejsou potřeba ke zpracování 2. Anonymizace dat → nahrazení dat jinými daty - A > B, B > F a podobně s tím, že legenda je offline nebo použití rozsahů 3. Maskování dat → v případě, že člověk řeší třeba regex nebo funkci, třeba pro kreditní kartu použije XXXX-XXXX-XXXX-1234 4. Odebrání nebo nahodilost metadat → v případě, že se nahrává soubor, odeberou se všechna metadata anebo se záměrně upraví na chybná 5. Používání dočasných chatů/chatů bez spojitosti s profilem → pokud to jde použít dočasný chat anebo nenavazovat chat na profil používaný na něco jiného
Pak už jsou tady pokročilejší věci, které jsem řešil na pár HIPAA a více citlivých projektech, tam se řešilo třeba:
a) Opt-out z toho, aby daná služba mohla použít ta data pro trénink
b) Vlastní modely vycházející z veřejně dostupných modelů
c) Tvorba kompletně vlastních modelů od začátku do konce
d) Podrobnější logging a auditing toho, co se děje a jak dlouho se vše uchovává
e) Korporáty si často tohle hlídají skrz DLP procesy a nástroje tak, aby se zabránilo lidské chybě
TL;DR → je důležitý si (buď jako jednotlivce nebo organizace) vyhodnotit celkový rámec v rámci bezpečnosti a soukromí těch dat a jaký s tím souvisí rizika a dle toho pak upravit ten proces tak, ať je tam korelace mezi citlivostí/typem dat a stráveným časem nad tím procesem samotným.
Super téma! Přijde mně hodně důležitý se o tom bavit, lidi strkají do různých AI chatů věci hlava nehlava, je to trochu časovaná bomba.
Obecně mně ty současné AI technologie přijdou bezpečnostně jako velmi křehké prostředí. Je v nich nainvestovaná strašná hromada peněz (jen OpenAI prodělává miliony dolarů denně), nervozita stoupá, všichni zuřivě hledají další trénovací data a není to zrovna obor, který by proslul velkým respektem k autorským právům. Proto jsem obecně hodně opatrný, co jim dávám za data, a beru je spíš jako nedůvěryhodného hráče – jsem hodně defenzivní a radši počítám s tím, že ta data můžou někde uváznout v tréninkové sadě víceméně bez ohledu na uživatelské nastavení. Lokální modely mají v tomhle velkou výhodu.
Gemini, like many large language models, processes information within its active session. This means that while it can access and process a vast amount of information from its training data, it doesn’t store individual user inputs or conversations beyond the current interaction.
To říká ten model, nebo dokumentace? Pokud to říká ten model, tak je ta informace prakticky bezcenná. Pokud dokumentace, je to o něco lepší, ale pořád je tu možnost leaknout ta data například omylem, kreativním výkladem podmínek služby a podobně. (Viz reklamní průmysl a jeho nakládání se soukromím uživatelů.)
Gemini doesn’t use your prompts or its responses as data to train its models.
Nicméně jak píše @zoul, tohle samo o sobě řeší jen jedno riziko a nějakou rovinu; navíc pokud je člověk skeptickej, otázkou je, zda je tohle statement, kterýmu může člověk důvěřovat, kór s citlivými daty.
+1, tohle je přesně ono. Navíc prostě OpenAI a její non-profit status a cíle jsou taky na dost komplexní diskuzi. Na konci dne velcí hráči budou řešit, jak v post-AI době dosáhnout co největšího profitu a podílu na trhu.
Tohle je nástroj, přes který jde zadávat prompty bez registrace a bez tréninku na vstupech - na tři různé AI nástroje.
Doporučuju pracovat jako s defaultním rozhraním, krásně jsou i vidět rozdíly ve výstupech, nemluvě o privacy důvodech
Je to už takřka rok a půl od mého původního dotazu, LLMka se v mezičase dost posunuly: máte k tématu nové poznatky? Jak s tím k březnu 2026 zacházíte? )
Mně aktuálně exploduje hlava ve snaze pochopit, jaké jsou hranice zpracování dat v Google Workspace. Existuje k tomu hezký rozcestníček (Privacy Hub), který nabízí tohle jasné shrnutí:
We want to be completely clear that generative AI does not change our foundational privacy protections that give you choice and control over your data:
Your interactions with Gemini stay within your organization. Gemini does not share your content outside your organization without your permission.
Your existing Google Workspace protections are automatically applied. Gemini brings the same enterprise-grade security as the rest of Google Workspace.
Your content is not used for any other customers. Your content is not human reviewed or used for Generative AI model training outside your domain without permission.
To zní dobře, ale je u toho tahle výluka:
For clarity this Privacy Hub only applies when you are using Gemini and NotebookLM with a qualifying edition of Google Workspace; Gemini for Education—a version of the Gemini app built for education institutions—or NotebookLM with Google Workspace for Education.
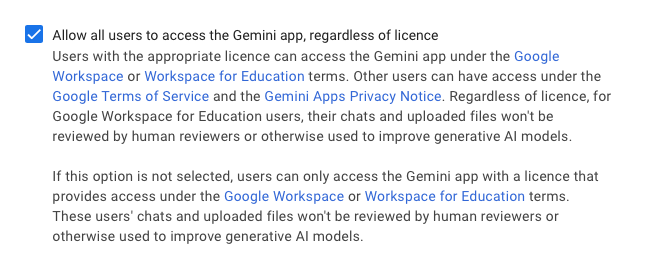
Z toho odkazu na „qualifying edition“ nejsem vůbec moudrý. V admin rozhraní Workspace je pak ohledně Gemini tenhle checkbox:
Takže můj aktuální zjednodušený dojem je, že používání různých AI funkcí v rámci Workspace zachovává soukromí a používání AI funkcí s běžnými osobními Google účty nikoliv. Zároveň ale platí obvyklá výluka ve smyslu „vaše data jsou soukromá, dokud explicitně nepožádáte o jejich sdílení“, viz výše:
Gemini does not share your content outside your organization without your permission.
Takže nás podle mě čeká permanentní UX hra na kočku a myš, podobně jako o cookie popupů. Já třeba aktuálně jako admin Workspace netuším, jestli někde není nějaký zahrabaný checkbox, kterým tenhle souhlas udělujeme. Orientujete se v tom někdo líp?
Začal jsem osobně i pracovně provozovat více LLM lokálně skrz bezpečnost, soukromí a i optimalizaci toho, jak používám třeba Claude, kde často lokální modely staží. Snažím se preferovat EU modely přes těmi z USA a modelům z Číny se aktuálně vyhýbám (i když nové Qwen modely jsou dle statistik bezvadný).
Ideálně bych pak chtěl mít eventuálně Mac Studio nebo Mac Mini a provozovat tam asistenta pro celou domácnost s tím, že by měl nicméně oddělenou identitu, docela pevný safety guardrails, neměl přístup třeba k mým emailům atd. Když budu něco potřebovat, tak to přepošlu (bude mít vlastní email). Hodně mě v tomhle inspiroval setup, co má Jaroslav Beck teďka, vnímám dost věcí podobně.
Samozřejmě co se týče Claudu a dalších cloudových LLM, tak tam je prima, že víc a víc lidí se učí s Markdown formátem (to byla vždy moje srdcovka) a přijde mi, že dost uživatelů se tím posunulo o level výš, více plánuje atd. Což je prima.
Že bych si provozoval nějaké LLMko lokálně zvažuju čím dál tím víc: je teď nějaký ověřený „go-to guy / místo”, odkud čerpat info, jak nad tím přemýšlet a ideálně postavit? Díky!
Lokální modely jsou samozřejmě ideál, ale fakt ti stačí? Zkoušel jsem třeba na svém MacBooku Pro (M1) přepisy přes Whisper a je to hrozně pomalý. Což je jeden aspekt, ale pak je tu i kvalita toho výstupu – měl jsem dojem, že lidi jsou rádi za každé i marginální zlepšení, takže ty lokální modely jsou pro ně příliš velký kompromis.
Jaky lokalni whisper jsi zkousel? Ja lokalne pouzivam ggml-large-v3-turbo-q8_0a na M4 macbooku jede v perfektni kvalite v EN i CZ (kdyz mu explicitne nastavim jazyk). Bezne tim diktuju a je to rychle i pohodlne. Je to stejne rychle jako whisper modely v cloudu (treba wispr flow).
Podle me je prave prepis mluveneho slova jeden z prvnich kompletne lokalne vyresenych AI casu.
Používám whisper-cpp z GitHubu s modelem turbo, čili asi to stejné? A nejasně jsem to napsal – zrovna u něj nereklamuju kvalitu (ta je opravdu stejná), ale rychlost, cloudový model přes API je masivně rychlejší. (Může to být ale i rozdíl mezi M1 a M4?)
Stačí je relativní zatím, protože pořád hledám tu hranici, co budu řešit lokálně na Raspberry Pi, co budu řešit lokálně na MacBooku (M2 Max, takže prima) a co budu řešit v cloudu. Zatím vnímám, že je to chaotický a úplně nevím, jak to roztřídit, takže tohle je WIP. Nicméně! Lokálně jsou některý automatizace/agenti a stejně tak konverzace typu brainstorming úplně v pohodě, zkouším aktuálně:
lfm2-24b-a2b-mlx-8bit
lfm2.5-1.2b-thinking-mlx-8bit
a na iPhonu Llama 3.2 1B
Co se týče přepisů, tak používám MacWhisper a tady mi dávalo smysl zaplatit za Pro verzi s tím, že jako model mám Parakeet v3, kterej je zatím úplně bezvadnej na EN i CZ, takže si nemůžu stěžovat.
Mám samozřejmě na Macu Ollamu jako každý druhý, ale poslední dobou se mi zalíbil i Osaurus, takže testuju ten.
Nevím, jak to vnímají ostatní, ale přijde mi to zatím jako divoký západ a čím víc se věnuju studii těch základních věcí (tzn. neuronový sítě, struktura LLM, tradiční automatizace vs. agenti), tak mi přijde, že hodně lidí i v Česku se tváří jako experti a tlačí tak svůj stack/setup přes placené kurzy, takže jsem dost opatrný doporučovat jednoho člověka, když se sám hodně učím a ty věci se dost mění.
Nicméně zdroje, které mi přišly poslední dobou fajn (bez nějakého pořadí):
Je to tak, hodně lidí si evidentně dobře internalizovalo poučku, že během zlaté horečky nejvíc bohatnou prodejci krumpáčů
Simona Willisona potvrzuji a ještě jsem v poslední době narazil na Rishiho Baldawu, který mně přijde naprosto skvělý v těch systémovějších důsledcích AI v programování, tedy třeba dopadech na code reviews a podobně. Ale to už jsem offtopic, pardon.