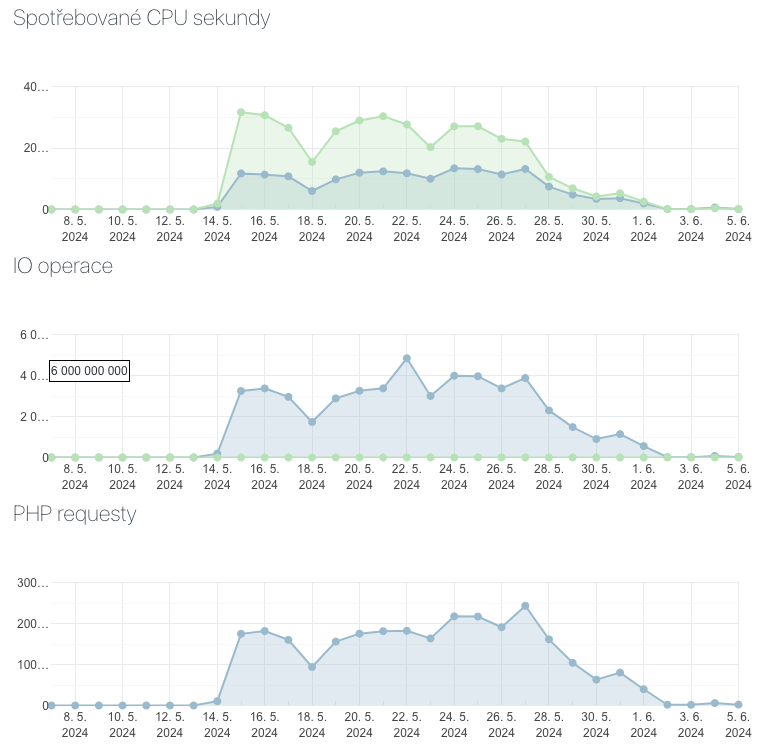
V minulém týdnu nám začal vypadávat server, v pátek už to dostoupilo kritické hranice, že všechny weby byly více nedostupné než dostupné. Nakonec jsme zjistili, že na nás “zaútočil” ClaudeBot (ClaudeBot/1.0; +claudebot@anthropic.com).
Píšu to v uvozovkách, protože to nebyl cílený, úmyslný útok, ale vyrovnalo se to DDOS útoku. Pokud si ho vyhledáte, tak je tímto v poslední době poměrně známý…
U nejpostiženějšího webu narostl počet requestů o 33 000 %.
Řešením je přidat tohoto robota do robots.txt, případně nasadit globální ban list na serveru – podle toho jaké máte možnosti.
A jak zjistí, že se nemění - dokud jej opakovaně celý neprojde? I Googlebot si mění rychlost indexování až postupně - když opakovaně nenajde změny (a když pak interně změní algoritmus, nemá problém vygenerovat třeba 3-4M requestů za 3 dny = klidně 700-1000 unikátních URL/minutu, 3 dny v kuse, navíc ze spousty IP adres)
Já si stěžuju, Googlebot nás smažil několik dnů, když se rozhodl ověřit úplně všechny URL, které zrovna měl v indexu (a zároveň je to bot, kterého fakt nechceš dát na blacklist ). U menších botů z jedné IP docela funguje nějaká forma ratelimitu nebo úplné blokace podle user-agenta. Ale je takových botů víc, co se rozhodnou rychle stáhnout kompletní web… nejspíš je někdo špatně napsal
Mě zatím “smaží” souvisle cca 14 dnů. Je to několik desítek (no spíš asi stovek) různých botů – ClaudeBot udělá denně cca 5–6 tisíc requestů, bing a google tak do 2000. Zbylých cca 240 000 udělají ti ostatní po pár stovkách.
Zkusil jsem ořezat funkcionalitu, která se jim asi líbila (facetové filtrování) a uvidím jestli je to přestane bavit, když budou dostávat stále stejné nefiltrované výsledky…
Tak to, po pár dnech, vypadá, že jsem z nehoršího venku. Grafy jsou z webhostingu websupportu, viděl jsem obdobný graf z (technologicky podobného) webu s reálnou návštěvností 10 000+ denně a ty hodnoty byly o řád nižší.
Last week, repair guide site iFixit said that Anthropic’s crawlers had hit its website nearly a million times in one day, and the coding documentation deployment service Read the Docs published a blog post saying that various crawlers had hit its servers at a huge scale. One crawler, it said, accessed 10 TB worth of files in a single day and 73 TB total in May: “This cost us over $5,000 in bandwidth charges, and we had to block the crawler,” they wrote. “We are asking all AI companies to be more respectful of the sites they are crawling. They are risking many sites blocking them for abuse, irrespective of the other copyright and moral issues that are at play in the industry.”
To je slušný úlet. Celý článek tady, nejspíš vyžaduje registraci, ale celkově to médium můžu doporučit:
Teď jsem někde viděl jak někdo Clade bota doporučoval, že dává lepší výsledky a je víc morální a etickej.
Co jsem mezitím zjistil (moje doměnka):
přijde robot přípravář, který jen stáhne strukturu webu – všechny URL, bez ohledu na jejich obsah, s respektem k robots.txt
předá (prodá?) databázi URL dalším robotům, kteří začnou indexovat přímo obsah, ale ty už na robots.txt kašlou
Jaké to má pro mě důsledky?
V okamžiku, kdy jsem upravil robots.txt (bylo už po kroku 1), tak už bylo pozdě. Nakonec jsem musel dotyčnou sekci webu přestěhovat na novou URL. Roboti začli dostávat 403 a po čase (týdny) toho nechali. Databáze od přípraváře, ale stále ještě někde koluje, takže na web průběžně přichází nový boti a snaží se o indexaci (momentálně např. Applebot/0.1; +http://www.apple.com/go/applebot…
Co jsem si z toho vzal
Musím mít logičtější filtrování, které nedovolí generovat miliony URL adres…
Jinak taky jsem videl zajimavou aktivitu botu na webu. Jsem zvedavy jestli ty ceny trafficu povedou k nejake zmene. Problem se statusem quo asi bude, ze nejvetsi drzitele obsahu (a tedy i vlastnici CDN/revenue CDN) maji temer veskery obsah za login/pay wallem. => netyka se jich to, pripadne to tem botum prodavaji k trenovani primo.
Takze za me spis sazim na postupny posun vseho, co pujde, za paywall.
Facetové vyhledávání, kdy jsem to měl nastavený tak, že to dovolovalo libovolnou kombinaci, která vrátí výsledek. Takže už při dvaceti položkách v jedné kategorii to hrozně naskakuje. Ty kategorie byly dvě a navzájem se vylučovali, ale v rámci jedné to bylo aditivní…
Omezil jsem to na možnost zaškrtnou jednu facetu z kategorie, čímž se počet možností dramaticky zredukoval… Nicméně to už bylo pozdě…
A to jsem měl nastavenou kanonickou url, ale tyhle ai roboti je prostě ignorujou. Třeba pro normálního google bota je to jedna URL.
a všechno to bylo vzájemně prolinkované? Kanonická adresa je až pro výsledky v indexu - bot ji musí navštívit a pak teprve zjistí, že kanonická je jinde. A občas to zkusí znovu, aby to zkontroloval
Nebylo. Ten robot to musel “naklikat”, nebo umělě vygenerovat ty adresy po tom co zjistil jakej je pattern. Jsou přeci jen inteligentní, takže je možný všecko…